This is the introductory post on a multi-part series, as I try to synthesize natural sounding human speech.
Computer generated speech has existed for a while now. However, the quality of generated speech is still not human, and is also not easy on ears. Although, they are catching up but even the production quality systems like Google Now, Apple’s Siri or Amazon Alexa are far off from what a human generated speech would sound like. This post is an attempt to explain how recent advances in the Speech Synthesis leverage Deep Learning techniques to generate natural sounding speech.
Brief introduction to traditional Text-to-Speech Systems
To understand why Deep Learning techniques are being used to generate speech today, it is important to understand how speech generation is traditionally done. There are two specific methods for Text-to-Speech(TTS) conversion. Parametric TTS and Concatenative TTS. It is also important to define two terms as mentioned in char2wav to judge the quality of generated speech. Intelligibility and Naturalness. Intelligibility is the quality of the audio generated. Is it clean, Is it listenable? And Naturalness is the quality of the speech generated. Does it sound emotionless? Does the speech has proper timing structure, and pronounciation?
Concatenative TTS: As the name suggests, this technique relies on high-quality audio clips(or units) recordings, which are then combined together to form the speech. Although the generated speech audio is very clean and clear but it sounds emotionless. Intelligible, but not Natural. This is because it is difficult to get the audio recordings of all possible words spoken in all possible combination of emotions, prosody, stress, etc. Naturally, these systems require huge databases, and hard-coding the combination to form these words. Developing a robust system takes seven to eight months.
Parametric TTS: Concatenative TTS is very restrictive, because of large data requirements and development time. So instead of a brute force like method, a more stastical method was developed. This method generates speech by combining parameters like fundamental frequency, magnitude spectrum etc. and processing them to generate speech. A Parametric TTS system will have two stages.
- First would be to first extract linguistic features after text processing. These features can be phonemes, duration, etc.
- Second would be to extract vocoder features that represent the corresponding speech signal. These features can be cepstra, spectrogram, fundamental frequency, etc. and they represent some inherent characteristic of human speech, and are used in audio processing. For example, Cepstra is the approximation of the transfer function in the human speech. This means that these features are hand engineered.
These hand engineered parameters, along with the linguistic features are fed into a mathematical model called a Vocoder. A vocoder takes in these features, and does multiple complex transforms on these features to generate the audio waveform. While generating the waveform, the vocoder estimates parameters of speech like phase, prosody(rhythm and stress), intonation, etc.
Parametrically synthesized speech is highly modular, and feasible. If we can make approximations of the parameters that make the speech, then we can train a model to generate all kinds of speech. And making such a system requires significantly less data and hard work than the Concatenative TTS.
Theoretically, this should work, but practically there are many artifacts resulting in muffled speech, with buzzing sound ever present, noisy audio. The generated speech is neither intelligible, nor natural. I will not go into the details, but with my understanding it boils down to this:
We are hard-coding certain features at every stage of the pipeline, and hoping to generate speech. These features are designed by us humans, with our understanding of speech, but they are not necessarily the best features to do the job. And this is where Deep Learning comes in.
Speech Synthesis with Deep Learning
As Andrew Gibiansky says, we are Deep Learning researchers, and when we see a problem with a ton of hand-engineered features that we don’t understand, we use neural networks and do architecture engineering.
Deep Learning models have proved extraordinarily efficient at learning inherent features of data. These features aren’t really human readable, but they are computer-readable, and they represent data much better for a model. This is another way of saying that a Deep Learning model learns a function to map input X to output Y.
Now working on this assumption, a natural sounding Text-to-Speech system should have input X as a string of text, and output Y as the audio waveform. It should not use any hand engineered features, and rather learn new high dimensional features to represent what makes speech, human. This is what I am trying to achieve.
The research in this field is very new, and I will build on these concepts. In this post I will survey the research, and will give only a brief overview. I will explain the details of these researches in later posts, as and when I pick them up to build upon, for my work.
Sample Level Generation of Audio Waveform
My objective is to generate speech. Audio files are represented in a computer by digitizing the audio waveform.
This is essentially a time-series of the audio samples. So instead of generating some latent parameter and then processing it to get the audio, it makes more sense to generate audio samples directly. The pioneering work in sample level audio generation with deep neural networks is WaveNet by DeepMind.
WaveNet: A Generative Model for Raw Audio
WaveNet generates the individual sample for the audio and each sample is conditioned on all the previous samples generated in the audio. This sample is then used with previous samples to generate the next sample. This is called autoregressive generation.
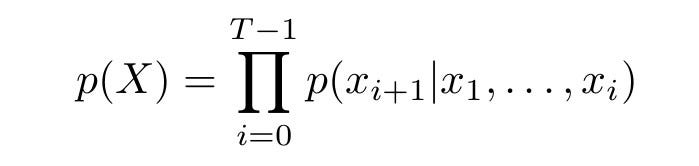
WaveNet is built using stacks of convolutional layers with residual, and skip connections in between. It takes digitized raw audio waveform as input, which then flows through these convolution layers and outputs a waveform sample.

One waveform sample generated at a time. Source: DeepMind Blog
The model is not conditioned, which means that it is not provided any information about the structure of the speech, so it does not generate any meaningful audio. If we train it on audio of humans speaking, it will generate sounds that will seem like humans are speaking words, but these words will be blabbering, and pauses and mumbling.
WaveNet team conditioned this model by providing vocoder parameters from a pre-existing TTS system as the other input along with the raw audio input. And the resulting Text-to-Speech system produced high-quality voice. They were very clean(no noise), no buzziness, no muffled speech.
However, this computation was very expensive. A typical WaveNet for high quality speech uses 40 such convolution layers, along with other connections in between. And since one sample is generated at a time, so generating 1 second of 16kHz audio requires processing 16000 samples. The WaveNet team reported that it takes around 4 minutes to generate 1 second of audio. This is not a feasible speech synthesis system, at least not with today’s technology, and the resources that I can afford. So I need to look into other methods. Baidu DeepVoice made WaveNet 400 times faster by implementing their kernels, and WaveNet team recently claimed to have made it 1000 times faster but they are yet to mention how.
Also, WaveNet at the time of release was not modular. It was conditioned on features generated from pre-existing TTS systems that requires hardcoded features. A modular solution would be end to end, where I can provide (text,audio) pairs, and let the model train. Baidu extended WaveNet in this direction.
But WaveNet proved that the quality of directly generating audio samples is significantly higher than using a vocoder with hand engineered features.
We don’t need to estimate the phase, intonation, stress, and other aspects of the speech, we just need to find the best architecture that will generate the appropriate samples. Another research to generate audio was SampleRNN.
SampleRNN
SampleRNN is another approach to generate audio samples and it uses a hierarchy of Recurrent Layers that have different clock-rates to process the audio. I will explain it in detail in my next post, but the idea is that multiple RNNs are connected in a hierarchy. The top level will take large chunks of inputs, process it and pass it to the lower level; the lower level will take smaller chunks of inputs, and pass it on further. This goes on up to the bottom-most level in the hierarchy, where a single sample is generated.
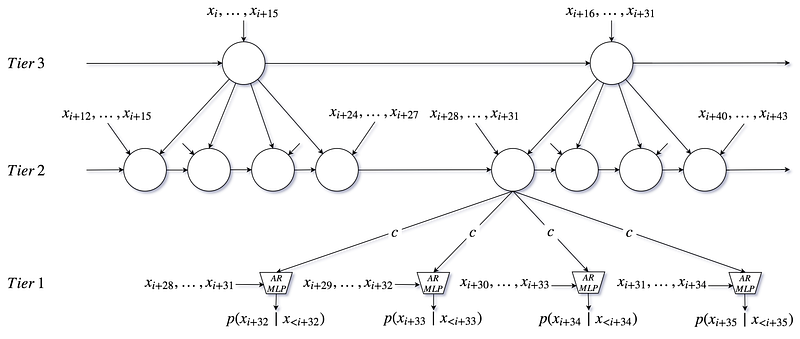
Three Tier SampleRNN
Just like WaveNet, this too is an autoregressive generative model. But it is computationally very fast compared to WaveNet.
Based on my calculation I believe that SampleRNN must be about 500 times faster than WaveNet. And, just like WaveNet, SampleRNN is an unconditional audio generator.
Char2Wav extends SampleRNN for speech synthesis by conditioning it on vocoder parameters. These vocoder parameters are generated from the text. Their results are not as good as WaveNet based TTS, but that is because the team did not train the model on enough data.
Not much experimentation is done on this model, but the quality of sound generated is quite good. Here is a model generating Mozart.
The audio samples generated by SampleRNN are as good as WaveNet and much faster, so I have decided to first try SampleRNN as a raw audio generator. A Neural Vocoder. And what features do I provide to condition SampleRNN? Tacotron by Google Brain research, answers this question. And in doing so they generated the most natural sounding speech generation system at the time this article is being written.
Tacotron: End-to-End Fully Text-to-Speech Synthesis
Where Tacotron shines is that it makes no assumption about what features should be passed to a vocoder, it makes no assumption about how the text should be processed. Tacotron team knows that humans do not know everything, and so they let the model learn the appropriate features ann processing. Thus, Tacotron goes to the character level.
I am building upon this architecture, and so I will write an article explaining how it works. But what it does is that it takes characters of the text as inputs, and passes them through different neural network submodules and generates the spectrogram of the audio. This looks more like a complete Deep Learning model for speech synthesis, and it does not require any features from the existing TTS systems unlike WaveNet.
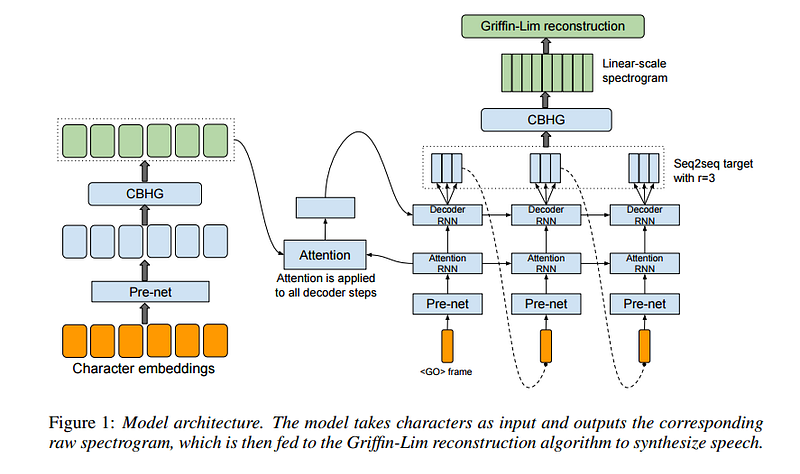
A Spectrogram is a good representation of the speech but it does not contain information about the phase, and so Griffin-Lim algorithm is used to reconstruct the audio by estimating the phase from the spectrogram. This algorithm, however, does a pretty shabby job of learning the phase, and except for the Tacotron’s official samples, I am yet to see audio samples generated by any open source implementation that does not have phase distortion. With Phase Distortion, the speech sounds as if an omnipotent being is speaking in a sci-fi setting, so it’s not that bad really.
Notice how natural the flow of speech sounds even if the audio quality is not the best.
Anyhow, I learned from the successes of WaveNet and SampleRNN that directly generating the samples works much better than reconstruction with traditional algorithms. Neural Vocoders have the ability to estimate phase, and other characteristics.
This has been proved by the Baidu’s Deep Voice 2 research. They connect Tacotron with their WaveNet synthesis model. The input to their WaveNet is the linear scale spectrogram output of Tacotron. They haven’t provided any audio samples generated by this system but they do report that (Tacotron + WaveNet) is significantly better than their Deep Voice 2 samples. Intuitively, it does seem right to connect a system like Tacotron with a Neural Vocoder. And their Deep Voice 2 samples are good enough in themselves, so I wonder how good the Tacotron + WaveNet will sound.
Now, to build my project I have used Tacotron to generate features. It has shown the best results out there, and it is more Deep Learning-y than WaveNet or Deep Voice, so personally, I can experiment more with it. Besides, it is an end to end model. This modularity enables experimentation with different datasets and different speaking styles.
I have used open source implementation of Tacotron for my first experiment and the results are not presentable, but that is most certainly because of the dataset I have used. It’s not sufficient or clean. Here is an example of what I have generated. The input text is similar to the Corpus I used for training.
You can notice the distorted phase. This is arising because the phase estimation algorithm is not perfect, so I am now working on building a neural vocoder.
With the resources that I can afford, I have decided to go with SampleRNN first. Compared to WaveNet, it is much easier to build and experiment with.
In my next post, I will explain the SampleRNN architecture. I am currently in the process of building a conditional SampleRNN model, and hopefully, by the time I write my next post in this series, I will have generated some audio samples from it. Stay Tuned!
Go Top
comments powered by Disqus